Note: 10x Genomics does not provide support for community-developed tools and makes no guarantees regarding their function or performance. Please contact tool developers with any questions. If you have feedback about Analysis Guides, please email analysis-guides@10xgenomics.com.
10x Genomics’ Universal 5’ Gene Expression products generate full-length, paired V(D)J sequences from individual cells, offering deep insights into the clonal diversity of immune receptors. Cell Ranger and Loupe Browser are powerful tools for analyzing the data generated from 10x Genomics experiments. For advanced analysis, consider adding MiXCR to your data analysis workflow. MiXCR enables advanced correction of PCR and sequencing errors and cross-cell contamination. Additionally, MiXCR offers individual/strain allele inference and the construction of B cell somatic hypermutation trees. It also integrates with bulk RNA-seq, repertoire sequencing data, and more. MiXCR extends immune repertoire analysis support to a range of species beyond just human and mouse, and allows the use of custom transcriptome references. Additionally, MiXCR facilitates the analysis of unconventional immune chains such as gamma delta (γδ) TCR repertoires.
MiXCR does not require knowledge of any coding language and allows you to analyze 10x Genomics Universal 5’ V(D)J data using simple preset commands. MiXCR completes pre-processing and analysis quickly, efficiently, and accurately on your local or cloud computational environment.
This document is an introduction to MiXCR. For detailed information about using MiXCR, please visit our detailed guides or getting started page.
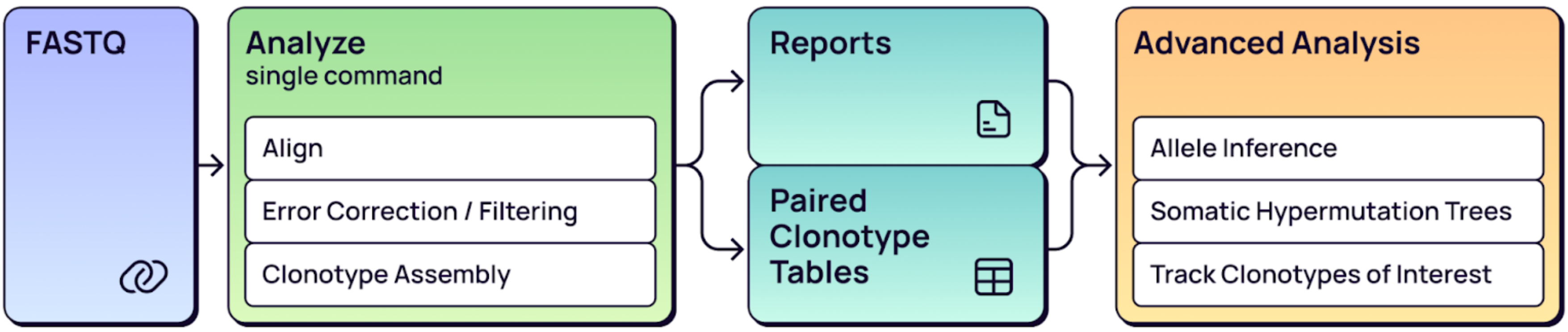
The MiXCR workflow consists of three parts:
Part 1: Upstream analysis
- Assemble contigs - Longer consensus chains are assembled from short reads in the FASTQ files.
- Alignment - Consensus sequences are aligned to the reference.
- Filtering - Alignments are filtered based on reads per UMI and UMI per cell distributions, lowering artificial diversity.
- Sequencing and PCR error correction - Multiple error correction steps reduce PCR and sequencing errors.
- Clonotype assembly - Full-length clonotype sequences are reconstructed.
- Chain pairing refinement - Cross cell contamination is removed and multiplets are resolved.
Part 2: Quality control
- QC report generation - Comprehensive text reports are created for every step of the pipeline.
- QC plot generation - Percent alignment, chain usage, and UMI/cell barcode distribution plots assessing quality of one or more samples are created.
Part 3: Downstream secondary analysis
- Somatic hypermutation trees generation
- Allele inference
- Link metadata to samples
- CDR3 characteristics analysis: strength, hydrophobicity, volume, charge, and more.
- Multiple diversity measures: Normalized Shannon-Wiener, Chao1, Gini Index, and more.
- Segment usage analysis
- Pairwise distance analysis
The MiXCR workflow must start with the raw sequencing data. This is usually a FASTQ file from your sequencing vendor of choice. MiXCR is equipped to analyze all 10x Genomics VDJ chemistries, including the GEM-X (5’ v3) chemistry.
Once you download and install the MiXCR package, working with MiXCR is as simple as typing in the 10x Genomics Preset into MiXCR. Upon initiation, MiXCR performs the upstream analysis (Part 1) and QC steps (Part 2) as summarized above. It then generates QC reports and a list of clones for paired TCRα/β or IG heavy/light chains. Afterwards you can proceed with the downstream secondary analysis (part 3).
MiXCR is a widely adopted analysis tool, with over 10 million samples analyzed, and has been cited in over 1,600 academic papers. Researchers choose MiXCR for its ease of use, extensive features, exceptional speed, and high accuracy.
Easy to use
Performing secondary analysis on 10x Genomics Universal 5’V(D)J data often requires the use of multiple tools and coding proficiency. However, MiXCR streamlines the entire process, including secondary analyses, into short commands. MiXCR provides dedicated presets for 10x Genomics: mixcr analyze 10x-sc-xcr-vdj or mixcr analyze 10x-sc-xcr-vdj-v3, making analysis simple and accessible even to those without coding skills.
Rich with features
MiXCR offers many analysis features to process all on market bulk or 10x Genomics Universal 5’ V(D)J data. Beyond core functionalities, here are some features you can use in MiXCR:
- Multimodal analysis: Integrate bulk, single cell, or Sanger data.
- Custom reference library: Align data to IMGT database, built-in curated library, or custom-made library.
- Supports many species: Analyze data from nonstandard species using custom library.
- Secondary analysis options: Take advantage of a comprehensive set of secondary analysis tools.
Fast processing speeds
Computational efficiency is crucial for immune system profiling, particularly when handling large single cell datasets. In benchmarking tests, MiXCR was faster, more sensitive, and more accurate than other popular tools like TRUST4 and Immcantation. Additionally, MiXCR allows for easy scalability of resource usage (e.g., CPU and memory) as per your data processing needs.
Highly accurate
Accuracy is paramount when working with complex immune sequencing data. MiXCR delivers highly accurate results with negligible error rates, even in the most challenging samples. The MiXCR analysis pipeline incorporates multiple error correction steps that eliminate errors from PCR, sequencing, and UMI artifacts. You can see examples of MiXCR’s accuracy in the benchmarking tests.
To get started with MiXCR, visit the MiXCR Getting Started page. It walks you through installation, using Docker, getting a license, and your first run. To take a deeper dive into MiXCR, read through the Analysis Overview.
Compatible with all operating systems. Requires Java 11.
To ask questions and interact with the MiXCR community, check out their GitHub or speak directly to the MiXCR team by emailing support at support@milaboratories.com.