Cluster mode is one of three primary ways of running Xenium Ranger. To learn about the other approaches, please go to the computing options page.
Xenium Ranger can be run in cluster mode using Slurm to run the stages on multiple nodes via batch scheduling. This allows highly parallelizable stages to utilize hundreds or thousands of cores concurrently, dramatically reducing time to solution.
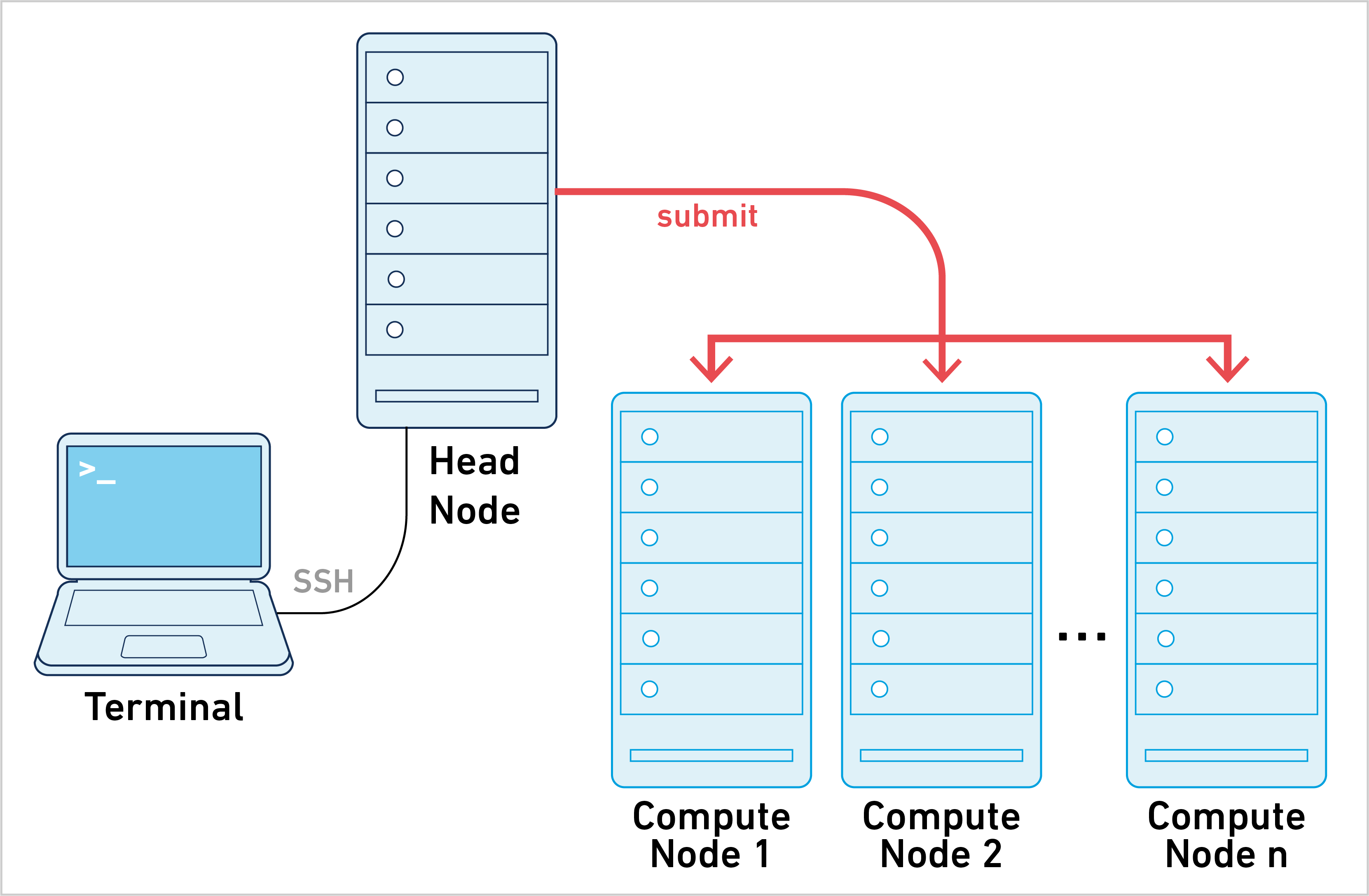
Running pipelines in cluster mode requires the following:
- Xenium Ranger is installed in the same location on all nodes of the cluster. For example,
/opt/xeniumranger-xenium1.6or/net/apps/xeniumranger-xenium1.6 - Xenium Ranger pipelines are run on a shared file system accessible to all nodes of the cluster. NFS-mounted directories are the most common solution for this requirement.
- The cluster accepts both single-core and multi-threaded (shared-memory) jobs.
Installing the Xenium Ranger software on a cluster is identical to installation on a local server. After confirming that the xeniumranger commands can run in single server mode, configure the job submission template that Xenium Ranger uses to submit jobs to the cluster. Assuming Xenium Ranger is installed to /opt/xeniumranger-xenium1.6, the process is as follows.
Step 1. Navigate to the Martian runtime's jobmanagers directory which contains example jobmanager templates.
cd /opt/xeniumranger-xenium1.6/external/martian/jobmanagers
ls
# output:
# bsub.template.example config.json slurm.template.example
Step 2. Make a copy of the cluster's example template to .template in the jobmanagers/ directory.
cp -v slurm.template.example slurm.template
# output:
# slurm.template.example -> slurm.template
ls
# output:
# bsub.template.example config.json slurm.template slurm.template.example
The job submission templates contain a number of special variables that are substituted by the Martian runtime when each stage is submitted. Specifically, the following variables are expanded when a pipeline is submitting jobs to the cluster.
| Variable | Must be present? | Description |
|---|---|---|
__MRO_JOB_NAME__ | Yes | Job names composed of the sample ID and stage being executed |
__MRO_THREADS__ | No | Number of threads required by the stage |
__MRO_MEM_GB__ __MRO_MEM_MB__ | No | Amount of memory (in GB or MB) required by the stage |
__MRO_MEM_GB_Per_THREAD__ __MRO_MEM_MB_Per_THREAD__ | No | Amount of memory (in GB or MB) rquired per thread in multi-threaded stages |
__MRO_STDOUT__ __MRO_STDERR__ | Yes | Paths to the _stdout and _stderr metadata files for the stage |
__MRO_CMD__ | Yes | Bourne shell command to run the stage code |
It is critical that the special variables listed as required are present in the final template you create. For more information on how the template should appear for a cluster, consult your cluster administrator or help desk.
Considerations for the different job schedulers are listed below.
SGE template:
For SGE cluster, you MUST replace <pe_name> within the example template to reflect the name of the cluster's multi-threaded parallel environment. To view a list of the cluster's parallel environments, use the qconf -spl command.
The most common modifications to the job submission template include adding additional lines to specify:
- The research group's queue. For example,
#$ -q smith.q - The account to which jobs will charge. For example,
#$ -A smith_lab
LSF template:
The most common modifications to the job submission template include adding additional lines to specify:
- Your research group's queue. For example,
#BSUB -q smith_queue - The account to which your jobs will charge. For example,
#BSUB -P smith_lab
To run a Xenium Ranger pipeline in cluster mode, add the --jobmode=slurm command line option when using the xeniumranger commands. It is also possible to use --jobmode=<PATH>, where <PATH> is the full path to the cluster template file.
There are two subtle variants of running Xenium Ranger pipelines in cluster mode, each with their own pitfalls. Check with your cluster administrator to see which approach is compatible with your institution's setup.
- Run
Xenium Rangerwith--jobmode=slurmon the head node. Cluster mode was originally designed for this use case. However, this approach leavesmrpandmrjobrunning on the head node for the duration of the pipeline, and some clusters impose time limits to prevent long running processes. - Use a job script to submit a
Xenium Rangercommand with--jobmode=slurm. With this approach,mrpandmrjobrun on a cluster mode. However, the cluster must allow jobs to be submitted from a compute node to make this viable.
When Xenium Ranger is run in cluster mode, a single library analysis is partitioned into hundreds and potentially thousands of smaller jobs. The underlying Martian pipeline framework launches each stage job using the sbatch command when running on Slurm cluster. As stage jobs are queued, launched, and completed, the pipeline framework tracks their status using the metadata files that each stage maintains in the pipeline output directory.
Like single server pipelines, cluster-mode pipelines can be restarted after failure. They maintain the same order of execution for dependent stages of the pipeline. All executed stage code is identical to single server mode, and the quantitative results are identical to the limit of each stage's reproducibility.
In addition, the Xenium Ranger UI can still be used with cluster mode. Because the Martian pipeline framework runs on the node from which the command was issued, the UI will also run from that node.
Stages in the Xenium Ranger pipelines each request a specific number of cores and memory to aid with resource management. These values are used to prevent oversubscription of the computing system when running pipelines in single server mode. The way CPU and memory requests are handled in cluster mode is defined by the following:
- How the
__MRO_THREADS__and__MRO_MEM_GB__variables are used within the job template. - How your specific cluster's job manager schedules resources.
For clusters whose job managers do not support memory requests, it is possible to request memory in the form of cores via the --mempercore command-line option. This option scales up the number of threads requested via the __MRO_THREADS__ variable according to how much memory a stage requires.
For example, given a cluster with nodes that have 16 cores and 128 GB of memory (8 GB per core), the following pipeline invocation command:
xeniumranger relabel --id=demo \
--xenium-bundle=xenium-bundle \
--jobmode=slurm \
--mempercore=8
will issue the following resource requests:
- A stage that requires 1 thread and less than 8 GB of memory will pass
__MRO_THREADS__of1to the job template. - A stage that requires 1 thread and 12 GB of memory will pass
__MRO_THREADS__of2to the job template because (12 GB) / (8 GB/core) = 2 cores. - A stage that requires 2 threads and less than 16 GB of memory will pass
__MRO_THREADS__of2to the job template. - A stage that requires 2 threads and 40 GB of memory will pass
__MRO_THREADS__of5to the job template because (40 GB) / (8 GB/core) = 5 cores.
As the final bullet point illustrates, this mode can result in wasted CPU cycles and is only provided for clusters that cannot allocate memory as an independent resource.
Every cluster configuration is different. If you are unsure of how your cluster resource management is configured, contact your cluster administrator or help desk.
SGE memory:
SGE supports requesting memory via the mem_free resource natively, although your cluster may have another mechanism for requesting memory. To pass each stage's memory request through to SGE, add an additional line to your sge.template that requests mem_free, h_vmem, h_rss, or the custom memory resource defined by your cluster.
cat sge.template ## Expected output #$ -N __MRO_JOB_NAME__ #$ -V #$ -pe threads __MRO_THREADS__ #$ -l mem_free=__MRO_MEM_GB__G #$ -cwd #$ -o __MRO_STDOUT__ #$ -e __MRO_STDERR__ __MRO_CMD__
Note that the h_vmem (virtual memory) and mem_free/h_rss(physical memory) represent two different quantities, and that Xenium Ranger stages __MRO_MEM_GB__ requests are expressed as physical memory. Using h_vmem in your job template may cause certain stages to be unduly killed if their virtual memory consumption is substantially larger than their physical memory consumption. It follows that we do not recommend using h_vmem.
If you do use h_vmem in a template, it is recommended that you use the __MRO_MEM_GB_PER_THREAD__ or __MRO_MEM_MB_PER_THREAD__ variables instead of __MRO_MEM_GB__ and __MRO_MEM_MB__. To determine memory limits for a multicore job, SGE will multiply the number of threads by the value in h_vmem. The __MRO_MEM_GB__ and __MRO_MEM_MB__ variables already reflect the sum amount of memory across all threads needed to run the job. Using those variables as h_vmem will inflate the memory required for multi-threaded jobs.
LSF memory:
LSF supports job memory requests through the -M and -R [mem=...] options, but these requests generally must be expressed in MB, not GB. As such, your LSF job template should use the __MRO_MEM_MB__ variable rather than __MRO_MEM_GB__. For example,
cat bsub.template ## Expected output #BSUB -J __MRO_JOB_NAME__ #BSUB -n __MRO_THREADS__ #BSUB -o __MRO_STDOUT__ #BSUB -e __MRO_STDERR__ #BSUB -R "rusage[mem=__MRO_MEM_MB__]" #BSUB -R span[hosts=1] __MRO_CMD__
Some Xenium Ranger pipeline stages are divided into hundreds of jobs. By default, the rate at which these jobs are submitted to the cluster is throttled to at most 64 at a time and at least 100 ms between each submission to avoid running into limits on clusters which impose quotas on the total number of pending jobs a user can submit.
If your cluster does not have these limits or is not shared with other users, you can control how the Martian pipeline runner sends job submissions to the cluster by using the --maxjobs and --jobinterval parameters.
To increase the cap on the number of concurrent jobs to 200, use the --maxjobs parameter:
xeniumranger resegment --id=sample ... --jobmode=slurm --maxjobs=200
You can also change the rate limit on how often the Martian pipeline runner sends submissions to the cluster. To add a five-second pause between job submissions, use the --jobinterval parameter:
xeniumranger resegment --id=sample ... --jobmode=slurm --jobinterval=5000
The job interval parameter is in milliseconds. The minimum allowable value is 1.