The computational pipeline cellranger count or multi for 3' Single Cell Gene Expression involves the following analysis steps.

The key read processing steps are outlined in this figure and described in the text below.
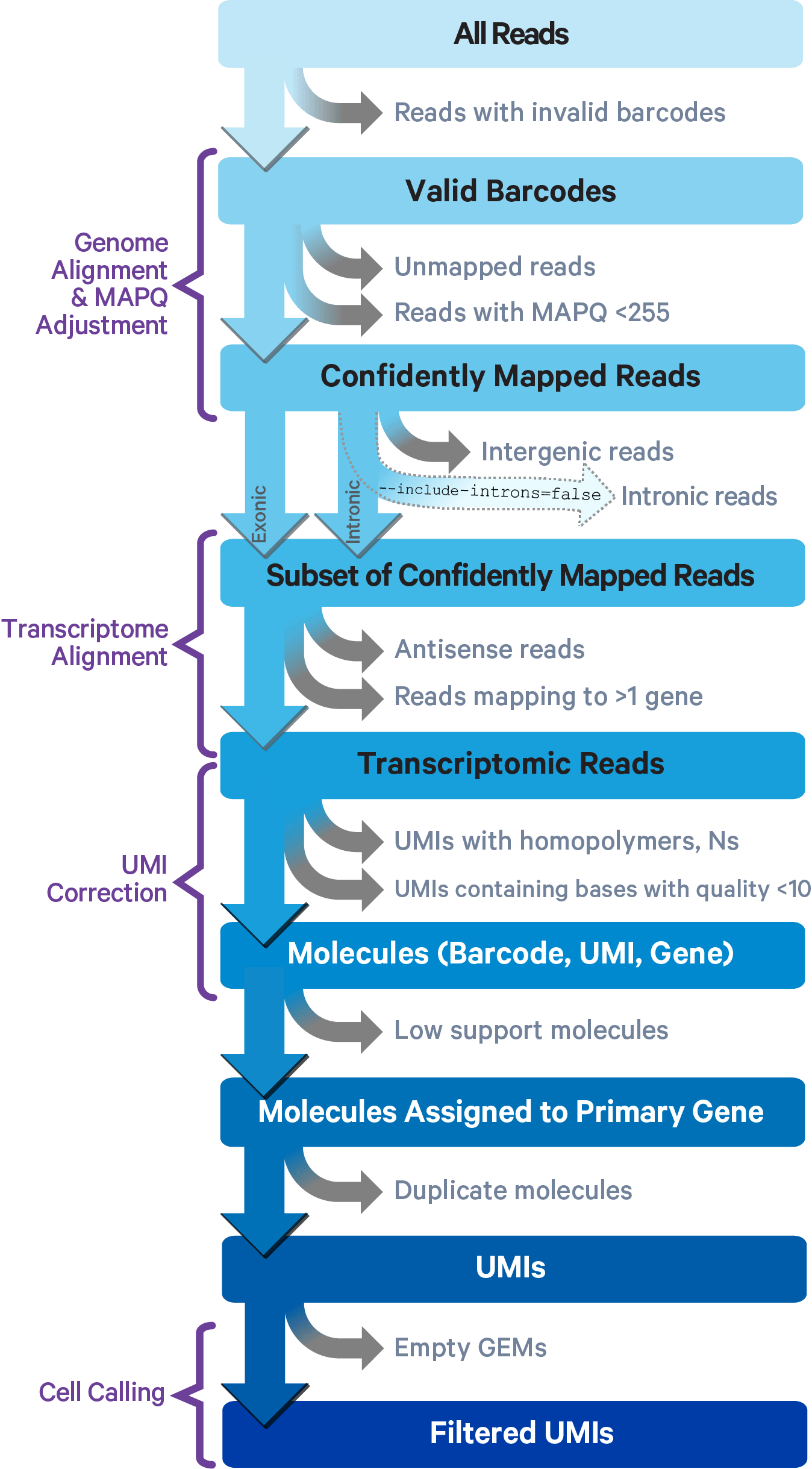
This section on read trimming applies to 3' Gene Expression assays.
Each full-length cDNA construct is flanked by a 30-bp template switch oligo (TSO) sequence (AAGCAGTGGTATCAACGCAGAGTACATGGG) at the 5' end and a poly-A sequence at the 3' end. The fragment size distribution of the sequencing library influences the likelihood of sequencing reads containing these sequences; reads derived from shorter RNA molecules are more prone to include both TSO and poly-A sequences compared to those from longer RNA molecules.
Due to the presence of non-template sequences in the form of either TSO or poly-A, low-complexity ends can complicate read mapping. As a result, the TSO sequence is trimmed from the 5' end and the poly-A is trimmed from the 3' end of Read 2 before alignment. This trimming enhances the sensitivity of the assay and improves the computational efficiency of the software pipeline.
The tags ts:i and pa:i in the output BAM files indicate the number of TSO nucleotides trimmed from the 5' end of Read 2 and the number of poly-A nucleotides trimmed from the 3' end. These trimmed bases are present in the sequence of the BAM record, and the CIGAR string reveals the position of these soft-clipped sequences.
Cell Ranger employs the STAR aligner for splicing-aware alignment of reads to the genome. It categorizes reads into exonic, intronic, or intergenic based on their alignment, using the transcript annotation GTF file. A read is classified as exonic if at least 50% of it overlaps with an exon. It is deemed intronic if it does not qualify as exonic but intersects an intron, and it is labeled intergenic if it fits neither of the previous categories.
For reads that align to a single exonic locus but also align to one or more non-exonic loci, the exonic locus is prioritized and the read is considered to be confidently mapped to the exonic locus with MAPQ 255.
Cell Ranger further aligns confidently mapped exonic and intronic reads to annotated transcripts by examining their compatibility with the transcriptome. As shown below, reads are classified based on whether they are exonic (light blue) or intronic (red) and whether they are sense or antisense (purple).
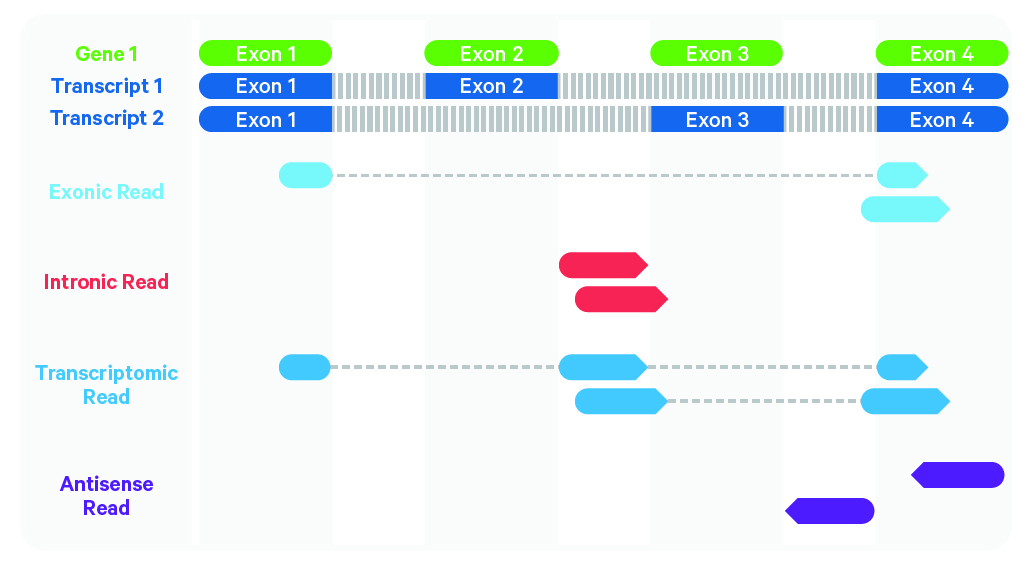
Starting in Cell Ranger v7.0, by default, the cellranger count and cellranger multi pipelines will include intronic reads for whole transcriptome gene expression analysis. Any reads that map in the sense orientation to a single gene - the reads labeled transcriptomic (blue) in the diagram above - are carried forward to UMI (Unique Molecular Identifier) counting. Cell Ranger ignores antisense reads (purple). As shown above, antisense reads are defined as any read with alignments to an entire gene on the opposite strand and no sense alignments. Consequently, the web summary metrics "Reads Mapped Confidently to Transcriptome" and "Reads Mapped Antisense to Gene" will reflect reads mapped confidently to exonic regions, as well as intronic regions. The default setting that includes intronic reads is recommended to maximize sensitivity, for example in cases where the input to the assay consists of nuclei, as there may be high levels of intronic reads generated by unspliced transcripts.
To exclude intronic reads, include-introns must be set to false. In this case, Cell Ranger still uses transcriptomic (blue) reads with sense alignments (and ignores antisense alignments) for UMI counting, however a read is now classified as antisense if it has any alignments to a transcript exon on the opposite strand and no sense alignments.
Furthermore, a read is considered uniquely mapping if it is compatible with only a single gene. Only uniquely mapping reads are carried forward to UMI counting (see this page for methods to check for multi-mapped reads).
To determine whether a barcode sequence is correct, Cell Ranger compares the sequence to the known barcodes for a given assay chemistry, which are stored in a barcode inclusion list file.
Cell Ranger uses the following algorithm to correct putative barcode sequences against the inclusion list:
- Count the observed frequency of every barcode on the inclusion list in the dataset.
- For every observed barcode in the dataset that is not on the inclusion list and is at most one Hamming distance away from the inclusion list sequences:
- Compute the posterior probability that the observed barcode did originate from the inclusion list barcode but has a sequencing error at the differing base (by base quality score).
- Replace the observed barcode with the inclusion list barcode that has the highest posterior probability (>0.975).
The corrected barcodes are used for all downstream analysis and output files. In the output BAM file, the original uncorrected barcode is encoded in the CR tag, and the corrected barcode sequence is encoded in the CB tag. Reads that cannot be assigned a corrected barcode will not have a CB tag.
Prior to UMI counting, Cell Ranger attempts to correct sequencing errors within UMI sequences. Reads that are confidently mapped to the transcriptome are placed into groups that share the same barcode, UMI, and gene annotation. If two groups of reads have the same barcode and gene but their UMIs differ by a single base (i.e., are one Hamming distance apart), it implies a probable base substitution error. In this case, the UMI for the group with lesser support is adjusted to match the more prevalent UMI.
Cell Ranger again groups the reads by barcode, UMI (possibly corrected), and gene annotation. If two or more groups of reads have the same barcode and UMI, but different gene annotations, the gene annotation with the most supporting reads is kept for UMI counting, and the other read groups are discarded. In case of a tie for maximal read support, all read groups are discarded, as the gene cannot be confidently assigned.
After these two filtering steps, each observed barcode, UMI, gene combination is recorded as a UMI count in the unfiltered feature-barcode matrix. The number of reads supporting each counted UMI is also recorded in the molecule info file.
Cell Ranger's cell calling algorithm is based on two primary algorithms: Order of magnitude (OrdMag) and EmptyDrops.
Step 1: High RNA content cell identification (OrdMag)
Initially, the algorithm identifies cells with high RNA content by setting a cutoff based on the total UMI count for each barcode. Cell Ranger can either take an expected number of recovered cells as input (using the --expect-cells parameter for count or multi) or estimate this number automatically (starting from v7.0).
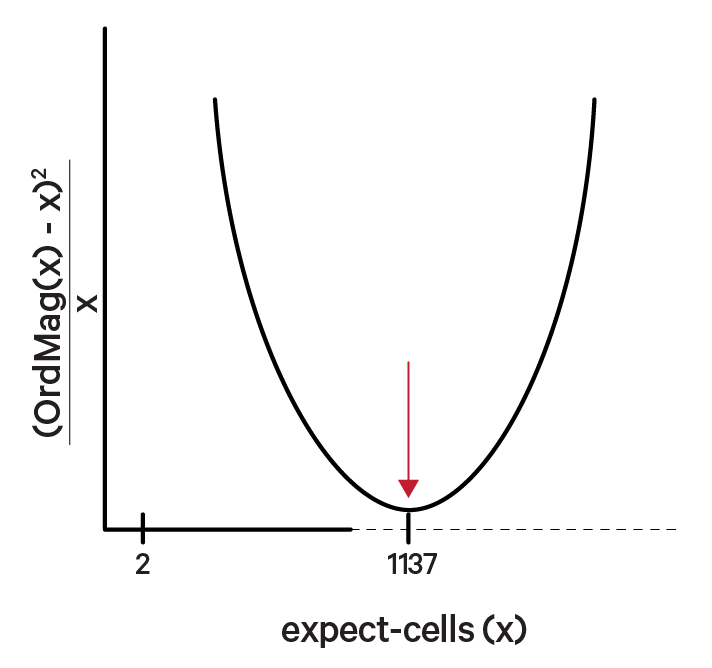
The OrdMag algorithm estimates the initial number of recovered cells by calling barcodes as cells if their total UMI counts exceed m/10, where m is the 99th percentile of the top N barcodes based on total UMI counts. The estimation process involves finding a value x that approximates OrdMag(x) by minimizing a loss function:
Cell Ranger's grid-search ranges from 2 to ~45,000 cells for NextGEM chemistries and 2 to ~80,000 for GEM-X chemistries.
In the example below, the optimized value for expect-cells is 1,137:
Step 2: Low RNA content cell identification (EmptyDrops)
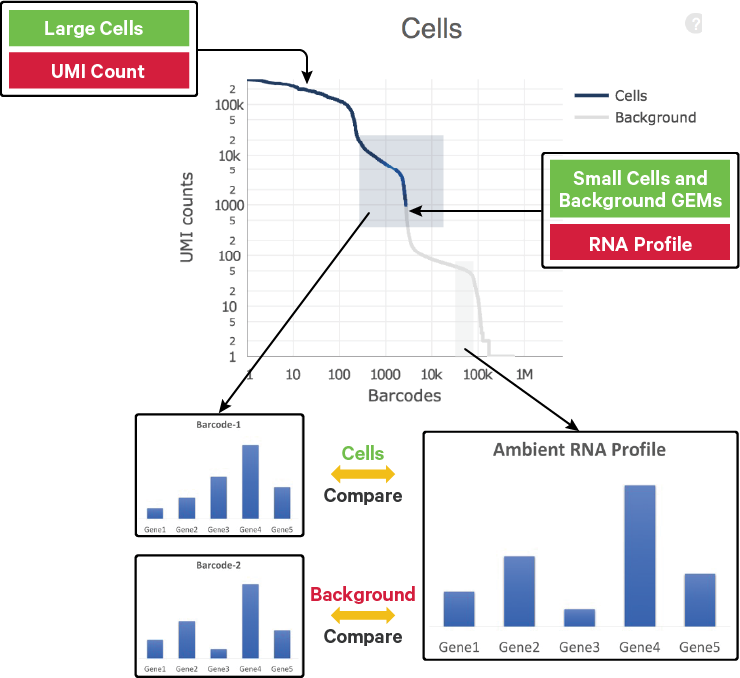
The EmptyDrops algorithm uses RNA profile information of the cells (built based on a background model) along with total UMI counts to distinguish between background RNA and cellular RNA UMIs.
The background model is a multinomial distribution parameterized by the ambient gene profile. The Simple Good-Turing smoothing algorithm estimates the ambient profile from the counts of all the genes in the background, ensuring non-zero proportions for genes that have zero counts across all the barcodes in the ambient range.
The candidate barcodes evaluated by EmptyDrops meet two criteria: they have more than 500 UMIs and have UMI counts higher than the maximum observed in the ambient background range, excluding barcodes called by OrdMag.
These candidate barcodes are compared to the background model. Barcodes with RNA profiles that significantly deviate from the background model are added to the set of cell calls. This process ensures that cells distinguishable from empty GEMs, even with much lower RNA content, are identified.
Custom barcode selection
In some cases, the set of barcodes identified as cells may not match the desired set based on visual inspection. To address this, users can:
- Re-run
countorreanalyzewith the --force-cells option. - Select the desired barcodes from the raw feature-barcode matrix in downstream analysis.
- Perform custom barcode selection by specifying --barcodes to
reanalyze.
This approach allows for flexibility and customization in identifying cell barcodes that best match the experimental conditions.
When using Cell Ranger in Feature Barcode Only Analysis mode, only step 1 of the cell calling algorithm is used. The cells called by this step of the algorithm are returned directly.
When multiple genomes are present in the reference (for example, Human and Mouse, or any other pair), Cell Ranger runs a special multi-genome analysis to detect barcodes associated with partitions where cells from two different genomes were present. Among all barcodes called as cell-associated (See Calling cell barcodes), they are initially classified as Human or Mouse by which genome has more total UMI counts for that barcode. Barcodes with total UMI counts that exceed the 10th percentile of the distributions for both Human and Mouse are called as observed multiplets. Because Cell Ranger can only observe the (Human, Mouse) multiplets, it computes an inferred multiplet rate by estimating the total number of multiplets (including (Human, Human) and (Mouse, Mouse)). This is done by estimating via maximum likelihood the total number of multiplet GEMs from the observed multiplets and the inferred ratio of Human to Mouse cells. If this ratio is 1:1, the inferred multiplet rate is approximately twice the observed (Human, Mouse) multiplets.
PCA
In order to reduce the gene expression matrix to its most important features, Cell Ranger uses Principal Components Analysis (PCA) to change the dimensionality of the dataset from (cells x genes) to (cells x M) where M is a user-selectable number of principal components (via num_principal_comps). Before proceeding to PCA, the feature-barcode matrix is filtered to genes and barcodes with three or more total UMIs. The pipeline uses a python implementation of IRLBA algorithm, (Baglama & Reichel, 2005), which we modified to reduce memory consumption. The reanalyze pipeline allows the user to further reduce the data by randomly subsampling the cells and/or selecting genes by their dispersion across the dataset. Note that if the data contains Feature Barcode data, only the gene expression data will be used for PCA.
t-SNE
For visualizing data in 2-d space, Cell Ranger passes the PCA-reduced data into t-SNE (t-Stochastic Neighbor Embedding), a nonlinear dimensionality reduction method (Van der Maaten, 2014). The C++ reference implementation by Van der Maaten (2014) was modified to take a PRNG seed for determinism and to expose various parameters which can be changed in reanalyze. We also decreased its runtime by fixing the number of output dimensions at compile time to 2 or 3.
UMAP
Cell Ranger also supports visualization with UMAP (Uniform Manifold Approximation and Projection), which estimates a topology of the high dimensional data and uses this information to estimate a low dimensional embedding that preserves relationships present in the data (McInnes et al, 2018). The pipeline uses the python implementation of this algorithm by McInnes et al (2018). The reanalyze pipeline allows the user to customize the parameters for the UMAP, including n_neighbors, min_dist and metric etc. Below shows the t-SNE (left) and UMAP (right) visualizations of our public dataset 5k PBMCs.
| t-SNE | UMAP |
|---|---|
 |  |
Cell Ranger uses two methods for clustering cells based on expression similarity, both operating in the PCA space.
Graph-based
The graph-based clustering algorithm consists of building a sparse nearest-neighbor graph (where cells are linked if they among the k nearest Euclidean neighbors of one another), followed by Louvain Modularity Optimization (LMO; Blondel, Guillaume, Lambiotte, & Lefebvre, 2008), an algorithm which seeks to find highly-connected "modules" in the graph. The value of k, the number of nearest neighbors, is set to scale logarithmically with the number of cells. Additionally, it performs a cluster-merging step using hierarchical clustering of cluster medoids in PCA space. This step merges pairs of sibling clusters if there are no differentially expressed genes or antibody features between them (with a Benjamini-Hochberg adjusted p-value below 0.05).
The use of LMO to cluster cells was inspired by a similar method in the R package Seurat.
K-Means
Cell Ranger also performs traditional K-means clustering across a range of K values, where K is the preset number of clusters. In the web summary prior to Cell Ranger v1.3.0, the default selected value of K is that which yields the best Davies-Bouldin Index, a rough measure of clustering quality.
To test for differences in mean expression between groups of cells, Cell Ranger uses the exact negative binomial test proposed by the authors of the sSeq method (Yu, Huber, & Vitek, 2013). When the counts become large, Cell Ranger switches to the fast asymptotic negative binomial test used in edgeR (Robinson & Smyth, 2007).
For each gene and each cluster i, Cell Ranger tests whether the mean expression in cluster i differs from the mean expression across all other cells.
The mean expression of a feature for cluster i is calculated as the total number of UMIs from that feature in cluster i divided by the sum of the size factors for cells in cluster i. The size factor for each cell is the total UMI count in that cell divided by the median UMI count per cell (across all cells). The mean expression outside of cluster i is calculated in the same way. The log2 fold-change of expression in cluster i relative to other clusters is the log2 ratio of mean expression within cluster i and outside of cluster i. When computing the log2 fold-change, a pseudocount of 1 is added to both the numerator and denominator of the mean expression.
Note that Cell Ranger's implementation differs slightly from the sSeq paper: the size factors are calculated using total UMI count instead of using DESeq's geometric mean-based definition of library size. As with sSeq, normalization is implicit in that the per-cell size factor parameter is incorporated as a factor in the exact and asymptotic probability calculations.
To correct the batch effects between chemistries, Cell Ranger uses an algorithm based on mutual nearest neighbors (MNN; Haghverdi et al, 2018) to identify similar cell subpopulations between batches. The mutual nearest neighbor is defined as a pair of cells from two different batches that is contained in each other’s set of nearest neighbors. The MNNs are detected for every pair of user-defined batches to balance among batches, as proposed in (Polanski et al, 2020).
The cell subpopulation matches between batches will then be used to merge multiple batches together (Hie et al, 2019). The difference in expression values between cells in a MNN pair provides an estimate of the batch effect. A correction vector for each cell is obtained as a weighted average of the estimated batch effects, where a Gaussian kernel function up-weights matching vectors belonging to nearby points (Haghverdi et al, 2018).
The batch effect score is defined to quantitatively measure the batch effect before and after correction. First, a maximum of 10,000 cells are subsampled. For every cell, we calculate how many of its k nearest neighbors belong to the same batch, where k is 0.01*N nearest neighbors (N is the number of cells), and normalize it by the expected number of same batch cells when there is no batch effect. If there is no batch effect, we would expect that the nearest neighbors of each cell are evenly shared across all batches and the batch effect score is close to one. There is a batch effect if the batch effect score is greater than one. The batch effect score value is not comparable across experiments with different numbers and/or batch sizes.
In the example below, the PBMC mixture was profiled separately by Single Cell 3' v2 (brown) and Single Cell 3' v3 (blue). On the left is the t-SNE plot after aggregating two libraries without the batch correction, and on the right is the t-SNE plot with the batch correction. The batch effect score decreased from 1.81 to 1.31 with the chemistry batch correction.
| Without chemistry batch correction | With chemistry batch correction |
|---|---|
 | 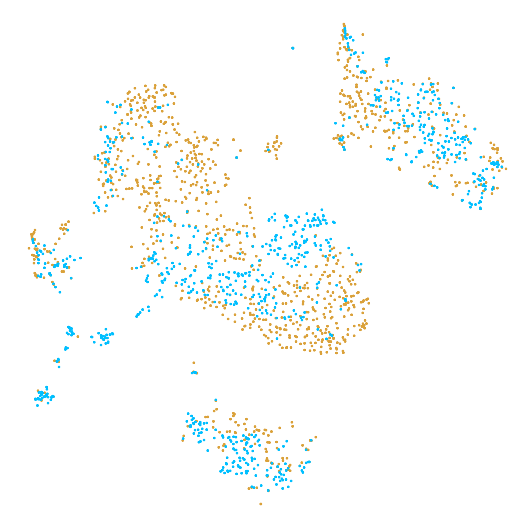 |
-
Baglama J and Reichel L. Augmented implicitly restarted Lanczos bidiagonalization methods. SIAM Journal on Scientific Computing 27: 19–42, 2005.
-
Blondel V, et al. Fast unfolding of communities in large networks. Journal of Statistical Mechanics: Theory and Experiment, 2008.
-
Haghverdi L, et al. Batch effects in single-cell RNA-sequencing data are corrected by matching mutual nearest neighbors. Nature Biotechnology 36, 2018.
-
Hie B, Bryson B, and Berger B. Efficient integration of heterogeneous single-cell transcriptomes using Scanorama. Nature Biotechnology 37: 685-691, 2019.
-
Lun A, et al. Distinguishing cells from empty droplets in droplet-based single-cell RNA sequencing data. Genome Biology 20, 2019.
-
McInnes L, Healy J, and Melville J. UMAP: Uniform Manifold Approximation and Projection for dimension reduction. arXiv, 2018.
-
Polanski K, et al. BBKNN: fast batch alignment of single cell transcriptomes. Bioinformatics 36: 964-965, 2020.
-
Robinson M and Smyth G. Small-sample estimation of negative binomial dispersion, with applications to SAGE data. Biostatistics 9: 321–332, 2007. Link to edgeR source.
-
Van der Maaten, LJP. Accelerating t-SNE using tree-based algorithms. Journal of Machine Learning Research 15: 3221-3245, 2014.
-
Yu D, Huber W, and Vitek O. Shrinkage estimation of dispersion in Negative Binomial models for RNA-seq experiments with small sample size. Bioinformatics 29: 1275–1282, 2013.