There are four primary ways to run Space Ranger:
- 10x Genomics Cloud Analysis: a scalable platform for data management, analysis, and collaboration to simplify and accelerate the interpretation of data generated from 10x Genomics assays.
- Single server: Space Ranger can run directly on a dedicated server. This is the most straightforward approach and the easiest to troubleshoot.
- Job submission mode: Space Ranger can run using a single node on the cluster. Less cluster coordination is required since all work is done on the same node. This method works well even with job schedulers that are not officially supported.
- Cluster mode: Space Ranger can run using multiple nodes on the cluster. This method provides high performance but is difficult to troubleshoot since cluster setup varies among institutions.
Here is a summary of our recommendations and requirements, in order of computational speed (left to right):
| Cluster Mode | Job Submission Mode | Single Server | |
|---|---|---|---|
| Recommended for | Organizations using an HPC with SGE or LSF for job scheduling | Organizations using an HPC | Users without access to an HPC |
| Compute details | Splits each analysis across multiple compute nodes to decrease run time | Runs each analysis on a single compute node | Runs each analysis directly on a dedicated server |
| Requirements | HPC with SGE or LSF for job scheduling | HPC with most job schedulers | Linux computer with minimum 8 cores & 64 GB RAM |
Cloud Analysis is a scalable platform for data management, analysis, and collaboration to simplify and accelerate the interpretation of data generated from 10x Genomics assays. Cloud Analysis makes it easier than ever to access and run 10x Genomics software, track and manage experimental data, and share that data with collaborators and researchers. Learn how to use the 10x Genomics Cloud.
The majority of the information on this website uses the single server approach. Follow the instructions below to analyze a 10x Genomics library:
- Generating FASTQs
- Specifying input FASTQs
- Single-library analysis
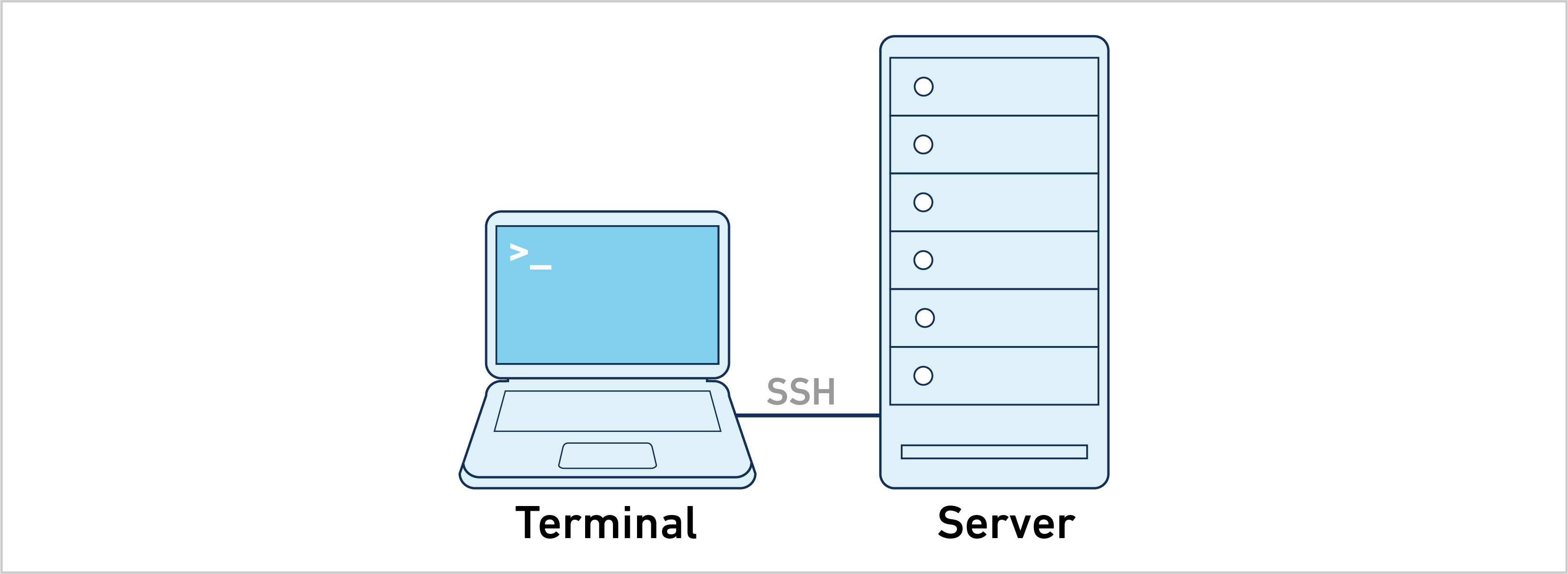
spaceranger with --localcores and --localmem to specify resource usage upper bounds. In practice, there is negligible return in allocating more than 32 cores or 256G to the pipeline.Space Ranger can be run in job submission mode, by treating a single node from the cluster like a local server. This leverages existing institutional hardware for pipeline analysis.
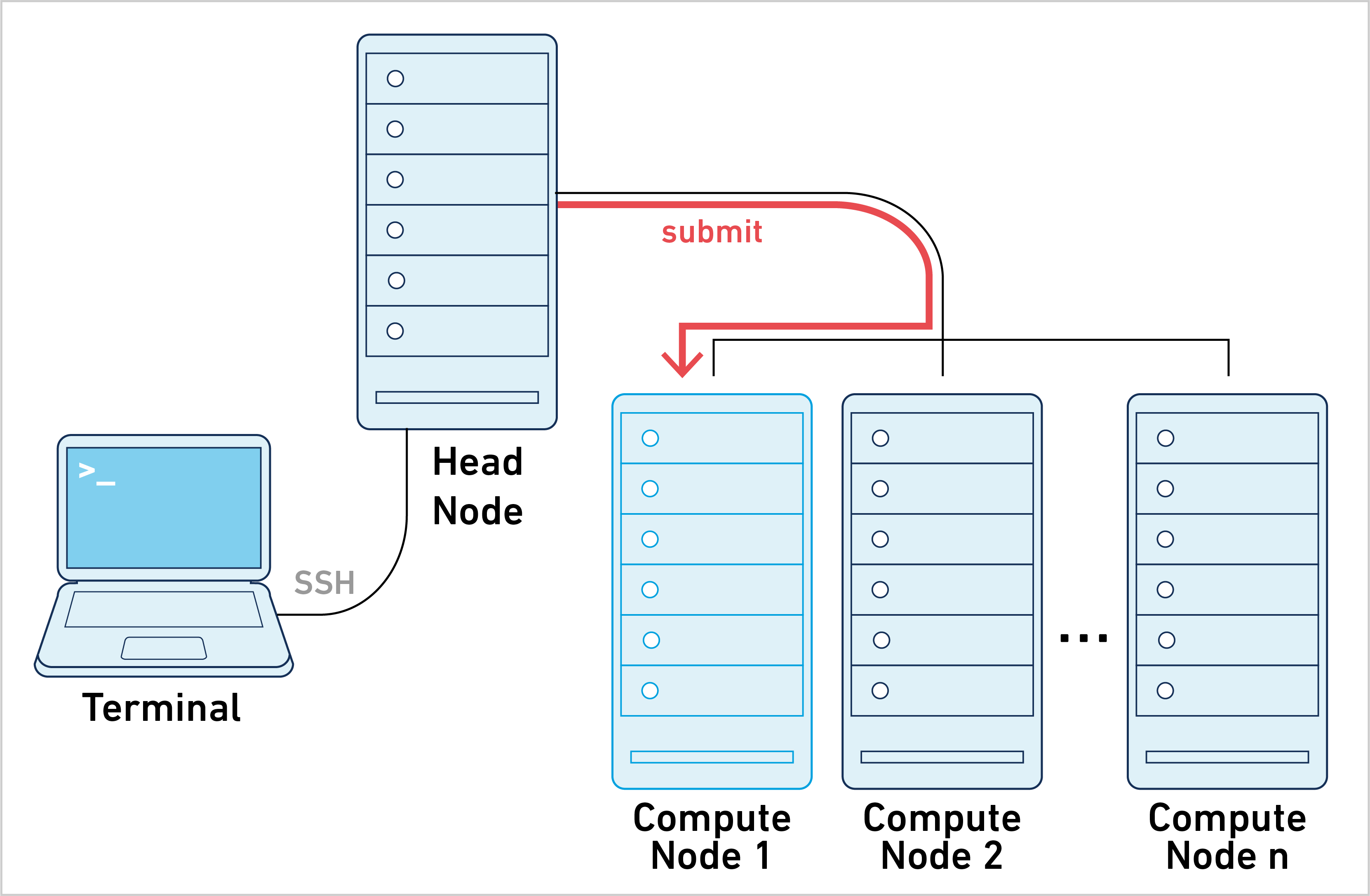
This mode of operation is what most people have in mind when it comes to working with clusters. A large computational job is submitted to the cluster and there is one job ID to track during job execution.
Space Ranger can be run in cluster mode to run the stages on multiple nodes via batch scheduling. This allows highly parallel stages to utilize hundreds or thousands of cores concurrently, dramatically reducing time to solution.
Instead of submitting one job to the cluster, Space Ranger creates hundreds, and potentially thousands, of small stage jobs. Each of these stage jobs needs to be queued, launched, and tracked by the pipeline framework. The necessary coordination between Space Ranger and the cluster makes this approach harder to set up and troubleshoot, since every cluster configuration is different.